
Institute of Tropical Medicine
Global Science for Health Worldwide
Tropical diseases, HIV/AIDS, tuberculosis, and inadequate health care affect the lives of billions of people worldwide.
Established in 1906, the Institute of Tropical Medicine (ITM) in Antwerp, Belgium, strives to advance science and health for all through innovative research, advanced education, professional medical services, and capacity sharing with partner institutions in Africa, Asia and Latin America. We aim to reduce the impact of diseases and health issues on populations globally.
For us, scientific excellence and societal impact are two sides of the same coin.

Celebrating 120 years of science
We have been advancing health and science for over a century, thanks to groundbreaking research, transformative education and global health services. Throughout this anniversary year, we honour our past and look ahead to a future shaped by our unimaginable breakthroughs.
Highlights

Register for the 2026 ITM Colloquium!
Registration is now open! Join us at our ITM Colloquium 2026 in Addis Ababa either in person or online. We warmly encourage you to attend in person to make the most of the conference, engage in discussions, and connect with colleagues from around the world.

The ITM book – out now!
The long‑anticipated book about ITM is here! Discover how we grew from a school of tropical medicine into an internationally respected centre for research, education, and innovation. Get your copy at the reception desk in the main building (Nationalestraat 155, 2000 Antwerp) or via Standaard Boekhandel.
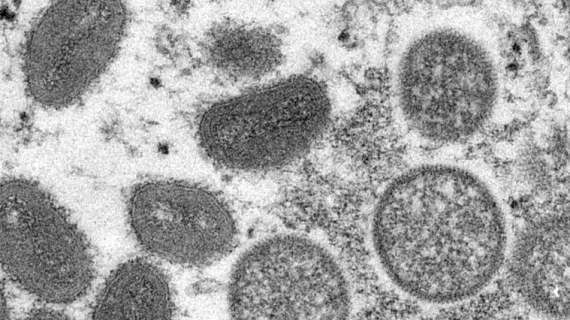
Read our Mpox FAQ
The number of mpox cases has been increasing. Read our frequently asked questions for more information.
News
All news-
 With the Fresh Off The Journal series, we bring you our monthly research highlights.
With the Fresh Off The Journal series, we bring you our monthly research highlights. -
Since the outbreak began, more than 1,400 people have been infected and more than 430 have died.
-
At the start of a major outbreak of a new mpox variant in the Democratic Republic of the Congo, infectious disease specialist Isabel Brosius (ITM) decided to travel to the region immediately.
-
Opinion pieces
The heat is here to stay and we need to make room for it
 Why do we keep treating heat — time and time again — as though it were a temporary emergency? This opinion piece by Stefanie Dens, architectural engineer and urban designer, was published in De Tijd.
Why do we keep treating heat — time and time again — as though it were a temporary emergency? This opinion piece by Stefanie Dens, architectural engineer and urban designer, was published in De Tijd. -
The award celebrates her exceptional career and contributions to the field of mycobacteriology.
-
Articles
Four ITM researchers awarded postdoctoral fellowships by the Research Foundation of Flanders
The four researchers will carry out vital work on viral spillover, leprosy transmission, mpox, and onchocerciasis-associated epilepsy -
Researching community health worker-led cardiovascular risk factor management and infectious diseases with epidemic potential
-
The award celebrates five decades of pioneering work on Ebola and other epidemic threats.
-
With the Fresh Off The Journal series, we bring you our monthly research highlights.
-
World View in Nature by Professor of Virology Kevin Ariën
-
Press releases
Launch of the IMPACT project to develop the first antibody-based countermeasure for orthopoxviruses
ITM brings mpox cohorts and antibody expertise to IMPACT -
Nova Academy evolves into a partnership of ten higher education institutions and will strengthen the lifelong learning mindset in Flanders.
-
Articles
Ebola outbreak in the DRC and Uganda
ITM is working closely with Congolese partners -
Press releases
Tiger mosquito season begins
Since 2022, the tiger mosquito has already been observed in 40 municipalities. -
Articles
Fresh Off The Journal: April 2026
With the Fresh Off The Journal series, we bring you eight research highlights every month.










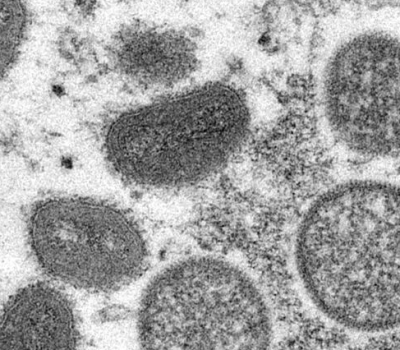



Our clinic
We are an outpatient clinic specialised in the diagnosis, treatment, and care of HIV/AIDS and other sexually transmitted infections, travel health and tropical medicine, and infectious diseases.
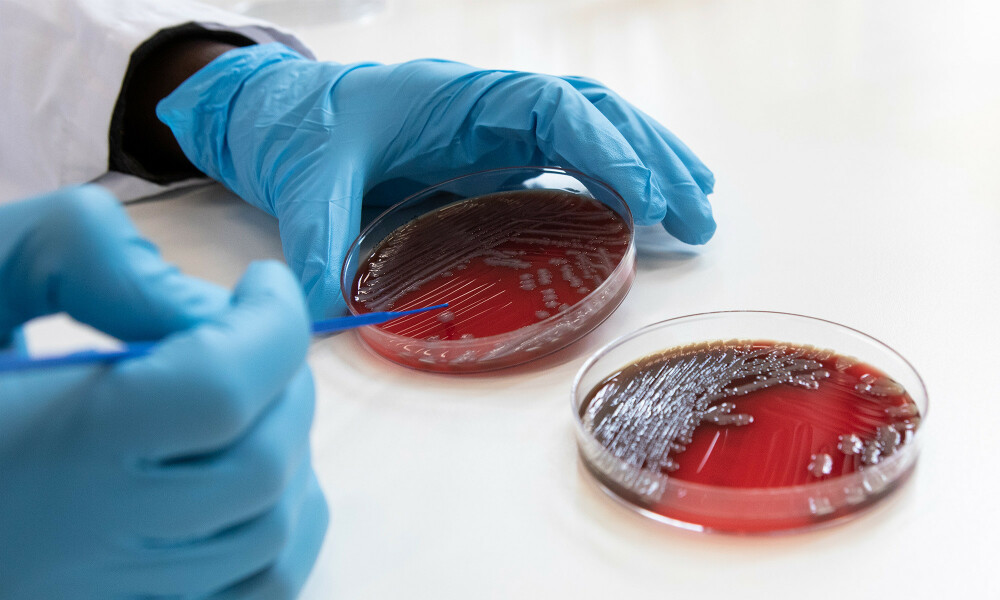
Our research
We aim to advance knowledge about tropical and infectious diseases and tackle important health challenges, with a particular focus on low-resource settings and vulnerable populations.
Our education
We offer master's programmes, postgraduate certificate programmes and expert short courses in tropical medicine, international public health and global One Health for professionals from around the world.

Our partnerships
We work with numerous partners across three continents on institutional capacity sharing and collaboration.

Make an appointment
Consultations in our polyclinic are by appointment only. Book your appointment well in advance, as waiting times can be long in spring and summer.

Contact
Do you want to get in touch? Browse our contact overview and find the right address for your question.

ITM merchandise
Get your hands on an ITM hoodie, notebook, pair of socks, boc 'n roll, and so much more! Check out our collection at the reception desk in the main building (Nationalestraat 155, 2000 Antwerp).
All events
Search eventsPhD defence Amani Kikula
ITG Onderwijscampus Rochus, Aula P.G. Janssen, Sint-Rochusstraat 43, 2000 Antwerpen
PhD defence Ni Ni Tun
ITG Onderwijscampus Rochus, Aula P.G. Janssen, Sint-Rochusstraat 43, 2000 Antwerpen
PhD defence Jil Molenaar
ITM , room Broden, Nationalestraat 155, 2000 Antwerpen